

Background on Kubernetes
Containerization enables development teams to move fast, deploy software efficiently and operate at scale. Kubernetes provides automated container orchestration and the management of containers in a highly available, distributed environment. The platform handles scaling, configuration and deployment of new versions of images and simplifies application deployment and management. At Redis, we are actively developing a Kubernetes-based deployment built on Redis Enterprise 5.x.
What to expect from this article
In previous blog posts, I talked about Kubernetes primitives and local Kubernetes development. In this post I’ll walk you through the simple 4-step process of deploying cloud-native Redis Enterprise on Kubernetes:
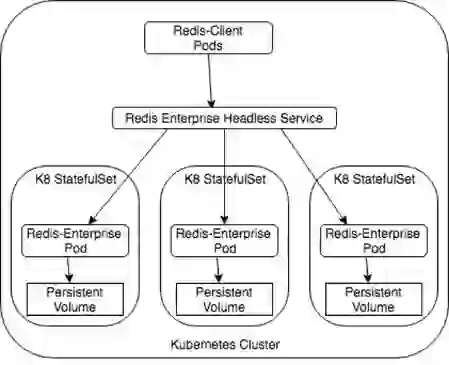
Detailed Walk-through
For this demo, we will use a managed Kubernetes cluster running on Google Cloud.

Once a cluster is created, store the license information using Kubernetes secrets primitives. In this example, we will set up a Kubernetes secret object called rp-secret. The command to create the secret object is shown below:
kubectl create secret generic rp-secret --from-file=license=<MY_REDIS_ENTERPRISE_LICENSE.txt --from-literal=username=<MY_USERNAME> --from-literal=password=<MY_PASSWORD>
The command should output the following:

Next, Deploy the headless service, controller and Redis statefulset manifests using yaml files* as shown in the following screenshots:
* We will publish the yaml files when Redis Enterprise for Kubernetes is made generally available.




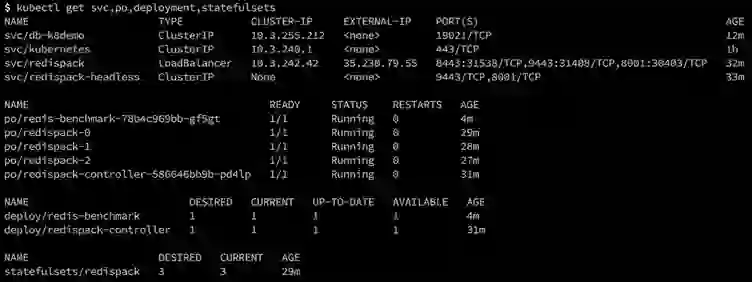
A Redis Enterprise three-node cluster with all running Kubernetes resources will look like this:
Upon successfully deploying Redis Enterprise on the Kubernetes cluster, create a database using the web interface.
Once the database is created using the web interface, the Redis Enterprise service controller will publish the endpoint of the database in the Kubernetes service catalog, as shown in the screenshot below for the database db-k8demo:

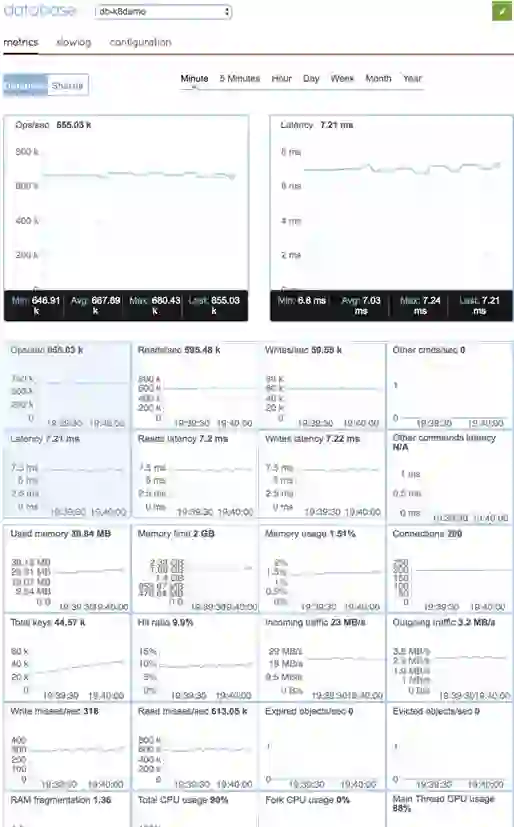
Using the published endpoint of the database in the Kubernetes service catalog, we perform a load test on our Redis database using a benchmarking tool called memtier_benchmark. The memtier tool is a command-line utility useful for generating and benchmarking NoSQL key-value databases. The load generated by the benchmark tool can be seen in the metrics section of the web interface of Redis Enterprise. The screenshot below shows the load generated by the memtier_benchmark tool on db-k8demo database.
Summing up
As organizations begin to use containers at large scale, orchestration frameworks become necessary to manage the increased complexity. While Kubernetes was initially developed to run stateless services, it’s also made running a stateful service such as the Redis Enterprise database much easier. With the rapid migration to cloud-native architectures and microservices, the combination of kubernetes and a super performant and highly available Redis Enterprise database will help organization innovate faster in the new era of application development and delivery. We’d love to hear more about how you would like to see Redis Enterprise in Kubernetes—please feel free to contact me directly for feedback.
For more information about Redis Enterprise, please visit our technical documentation and or release notes page.


