

We are happy to announce the general availability of RedisGears, a serverless engine that provides infinite programmability in Redis. Developers can use RedisGears to improve application performance and process data in real time, while architects can leverage it to drive architectural simplicity.
As a dynamic framework for the execution of functions that implement data flows in Redis, RedisGears abstracts away the data’s distribution and deployment to speed data processing using multiple models in Redis. RedisGears lets you program everything you want in Redis, deploy functions to every environment, simplify your architecture and reduce deployment costs, and run your serverless engine where your data lives.
RedisGears can be deployed for a variety of use cases:
In addition to announcing RedisGears, we’re also unveiling its first recipe. A “recipe” is a set of functions—and any dependencies they might have—that together address a higher-level problem or use case. Our first recipe is rgsync. Also referred to as write-behind, this capability lets you treat Redis as your frontend database, while RedisGears guarantees that all changes are written to your existing databases or data warehouse systems.
To help you understand the power of RedisGears, we’ll begin with an explanation of RedisGears architecture and its benefits. Then we’ll discuss how these benefits apply to write-behind and we’ll demonstrate its behavior via a demo application we created.
At the core of RedisGears is an engine that executes user-provided flows, or functions, through a programmable interface. Functions can be executed by the engine in an ad-hoc map-reduce fashion, or triggered by different events for event-driven processing. The data stored in Redis can be read and written by functions, and a built-in coordinator facilitates processing distributed data in a cluster.
In broad strokes, this diagram depicts RedisGears’ components:
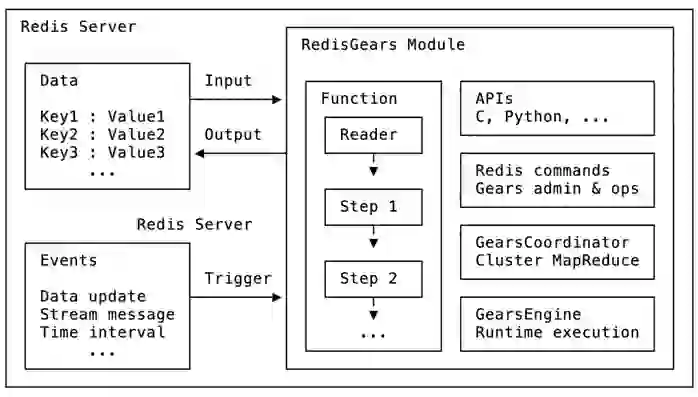
RedisGears has three main components:
On top of these three core components, RedisGears includes a fast low-level C-API for programmability. You can integrate this C-API via Python today, with more languages in the works.
RedisGears minimizes the execution time and the data flow between shards by running your functions as close as possible to your data. By putting your serverless engine in memory, where your Redis data lives, it eliminates the time-consuming round trips needed to fetch data, speeding processing of events and streams.
RedisGears lets you “write once, deploy anywhere.” You can write your functions for a standalone Redis database and deploy them to production without having to adapt your script for a clustered database.
Combining real-time data with a serverless engine lets you process data across data structures and data models without the overhead of multiple clients and database connectors. This simplifies your architecture and reduces deployment costs.
The ability to cope with sudden spikes in the number of users/requests is something modern companies and organizations must consider. Black Friday and Cyber Monday traffic, for example, can dwarf that of ordinary days.
Failure to plan for such peaks can lead to poor performance, unexpected downtime, and ultimately lost revenue. On the other hand, over-scaling your solution to these peaks can also be expensive. The key is to find a cost-efficient solution that can meet your demands and requirements.
Traditional relational/disk-based databases are often unable to deal with significant increases in load. This is where RedisGears comes into play. RedisGears’ write-behind capability relies on Redis to do the heavy lifting, asynchronously managing the updates and easing the load and diminishing the spikes on the backend database. RedisGears also guarantees that all changes are written to your existing databases or data warehouse systems, protecting your application from database failure and boosting the performance of your application to the speed of Redis. This simplifies your application logic drastically since it now only needs to talk to a single frontend database, Redis. The write-behind capability comes initially with support for Oracle, MySQL, SQL, SQLite, Snowflake, and Cassandra.
The diagram below displays the architecture of RedisGears’ write-behind capability:
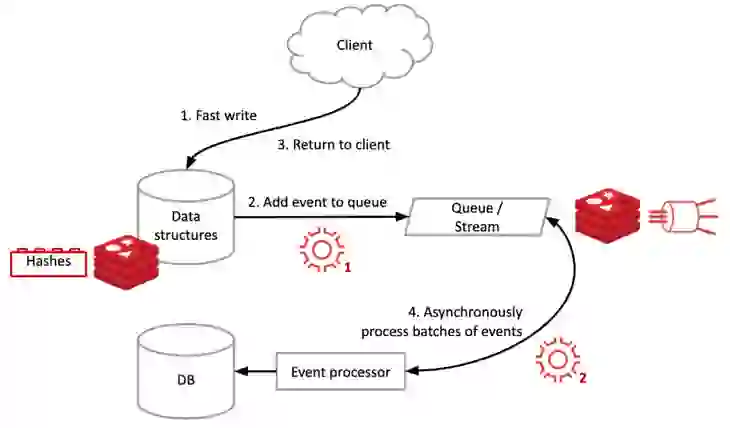
It operates as follows:
Together those two functions make up what we call a “recipe” for RedisGears. (Note that the recipe for write-behind is bundled in the rgsync (RedisGears sync) package, along with several other database-syncing recipes.)
As noted above, step three happens only when the event was successfully added to the stream. This means that if something goes wrong after the client gets the acknowledgement of the write operation, Redis replication, auto-failover, and data persistence mechanisms guarantee that the update event will not be lost. By default, the write-behind RedisGears capability provides the at least once delivery property for writes, meaning that data will be written once to the target, but possibly more than that in case of failure. It is possible to set the RedisGears function to provide exactly once delivery semantics if needed, ensuring that any given write operation is executed only once data is on the target database.
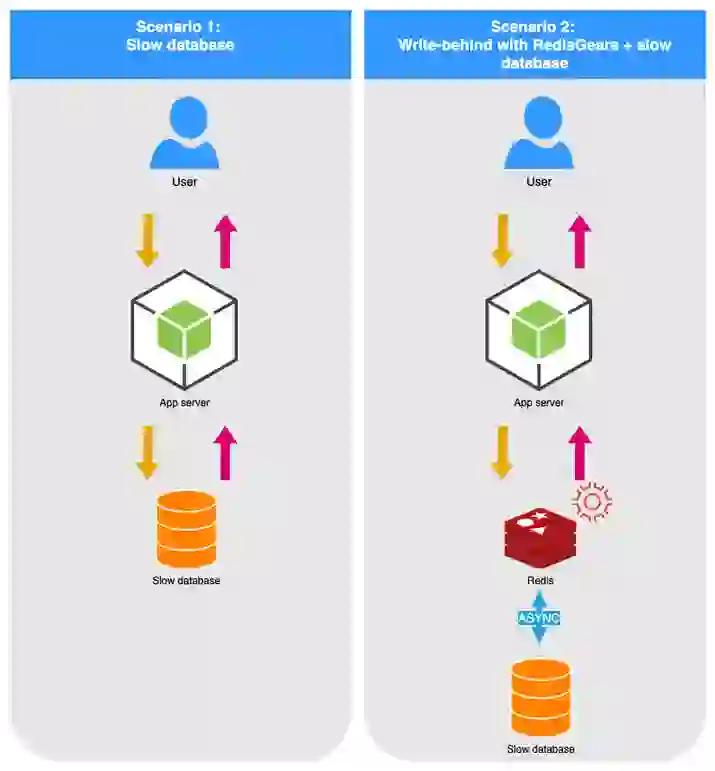
Improving application performance with write-behind
To showcase the benefits of write-behind, we developed a demo application in which we’ve added endpoints to enable two scenarios:
In this example, we used MySQL as the backend database for ease of testing and reproduction.
To simulate peaks in the application, we’ve created a spike test with k6, in which we simulate a short burst going from 1 to 48 concurrent users.
To check how the overall system handled the spike, we tracked the achieved HTTP load and latency on the application as well as the underlying database system performance. The graph below showcases both scenarios—the left interval presents results for the MySQL-only solution, while the right interval presents results for the write-behind scenario with RedisGears.

This chart displays some important findings:
We are really excited about RedisGears and write-behind. We believe that the write-behind use case is only the beginning of the infinite problems that RedisGears can solve.
We hope that this blog post has encouraged you to try RedisGears. Please check out RedisGears.io, which contains tons of examples and hints on how to get started. You can find more cool demos here:
A new version of RedisInsight will be released soon and will contain support for RedisGears to execute functions and to view the registered functions in RedisGears. We’ll leave you with a quick GIF of what you can expect:

Happy coding!



