



Getting Started with Redis Streams and Java
Learn more


Download the Tutorial: How to Build Apps using Redis Streams now
Redis Streams is a data type that provides a super fast in-memory abstraction of an append only log. The main advantages of Redis Streams are the highly efficient consumer groups, allowing groups of consumers to uniquely consume from different parts of the same stream of messages, and the blocking operations that allow a consumer to wait until a new data is added to the stream. With the release of version 5.0, Redis launched an innovative new way to manage streams while collecting high volumes of data — Redis Streams. Redis Streams is a data structure that, among other functions, can effectively manage data consumption, persist data when consumers are offline with a data fail-safe, and create a data channel between many producers and consumers. It allows users to scale the number of consumers using an app, enables asynchronous communications between producers and consumers and efficiently uses main memory. Ultimately, Redis Streams is designed to meet consumers’ diverse needs, from real-time data processing to historical data access, while remaining easy to manage.

I am personally guilty of describing streams in the wrong way—I’ve defined it as a “series of hashmap-like elements, ordered by time, under a single key.” This is incorrect. The last bit regarding time and key are OK, but the first bit is all wrong.
Let’s take a look at why streams are misunderstood and how they actually behave. We’ll evaluate the good and the bad of this misunderstanding and how it could affect your software. Finally, we’ll examine a few non-obvious patterns that take advantage of the little-known properties of Redis Streams.
Data processing has been revolutionized in recent years, and these changes present tremendous possibilities. For example, if we consider a variety of use cases — from the IoT and Artificial Intelligence to user activity monitoring, fraud detection and FinTech — what do all of these cases have in common? They all collect and process high volumes of data, which arrive at high velocities. After processing this data, these technologies then deliver them to all the appropriate consumers of data.
Redis Streams offers several possibilities for users, including the ability to integrate this new data structure into various apps. In order to make it easier for users to start using Redis Streams, we have written up a few tutorials to help get you started:
First, let’s look at the XADD command, as this is where the misunderstanding starts. The command signature as it stands in the official redis.io documentation looks like this:
XADD key ID field value [field value ...]
key is self-explanatory. id is the timestamp/sequence combo for the new entry, but in reality, it is almost always * to indicate auto generation. The root of this confusion starts with field and value. If you look at the command signature for HSET, you’ll see a pretty similar pattern:
HSET key field value [field value ...]
The signature for the two commands are only a single argument off and that argument in XADD is almost always a single *. Looks pretty similar, uses the same terms, must be the same, right?
OK. To continue the problem, let’s set aside Redis and look at how programming languages deal with field-value pairs. For the most part, no matter the language, the most representational way of articulating field-value is with a set (no repeats) of fields that correlate to values—some languages will retain order of fields and some will not. Let’s look deeper with a small cross-language comparison:
Language Structure Ordered fields Allows repeats
JavaScript & JSON Object ✗ ✗
JavaScript Map ✓ ✗
Python* Dict ✓ ✗
PHP Array ✓ ✗
Java HashMap ✗ ✗
C# Dictionary ✗ ✗
* The CPython implementation has maintained order for dict key-value pairs since 3.6 and prior to this OrderedDict has been available.
This maps nicely to Redis hashes—all of these can articulate the properties of a hash, which is unordered and has no repeats. PHP arrays, Python dicts, and JavaScript maps can define field order, but if you’re working with hashes in Redis, then it doesn’t matter, you just have to know that you can’t depend on this order at the application level.
For most people, the natural conclusion has been that since the command signatures of HSET and XADD have a correlation, then they probably have a similar correlation in return. Indeed, at the protocol level in RESP2, these both are returned as interleaved RESP Arrays. This is continued in early versions of RESP3 where the response for HGETALL and XREAD were both maps (more on that later).
Normally, I code in JavaScript and occasionally Python. As someone who communicates about Redis, I need to reach as many people as possible and these two languages are pretty well understood, so a demo or sample code in either will be understood by a high percentage of the developer world. Recently, I had the opportunity to talk at a PHP conference and needed to convert some existing Python code to PHP. I have used PHP on and off for close to 20 years, but it’s never been a passion of mine. The particular demo didn’t fit well into a mod_php style execution, so I used swoole and its co-routine execution (on a side note, being comfortable in the JavaScript world, swoole makes PHP very, very familiar for me). The library was a tad out-of-date and required sending raw Redis commands without any real client library assistance in decoding the returns in a high level way. Generally, sending raw Redis commands and decoding the results provides a little more control and isn’t onerous.
So, when sending commands to XADD, I was building the field-value portion and had an off-by-one error (chalk this up to diving back into PHP after years of absence). This resulted in me unintentionally sending something along the lines of:
XADD myKey * field0 value1 field0 value2 field2 value3
Instead of sending correlated fields and values (field0 to value0 and so on).
Later in the code, I was putting the results of XREAD into an existing PHP array (which is associative) in a loop, assigning each field as a key with each value and skipping anything already set. So, I started with an array like this:
array(1) {
["foo"]=>
string(3) "bar"
}
And ended up with an array like this:
array(3) {
["foo"]=>
string(3) "bar"
["field0"]=>
string(6) "value1"
["field2"]=>
string(6) "value3"
}
I could not fathom how that was possible. I was quickly able to track down the bug on why value1 got assigned to field0 (the above mentioned off-by-one error in my XADD), but why wasn’t field0 set as value2? In HSET, this behavior for adding fields is basically upsert—update a field if it exists, otherwise add the field and set the value.
Examining the MONITOR logs and replaying the values, I ran XREAD as follows:
> XREAD STREAMS myKey 0
1) 1) "myKey"
2) 1) 1) "1592409586907-0"
2) 1) "field0"
2) "value1"
3) "field0"
4) "value2"
5) "field2"
6) "value3"
Repeats are present and recorded, not upserted; additionally the order is preserved. This is nothing like a hash!
Thinking about this using JSON as an approximation, I thought stream entries looked like this:
{
"field1" : "value",
"field2" : "value",
"field3" : "value"
}
But they actually look like this:
[ ["field1", "value"], ["field2", "value"], ["field3", "value"] ]
Good news
If you have code that currently works with Streams and you’re assuming entries are like hash maps, you’re probably fine. You just need to watch for potential bugs regarding putting in duplicate fields, as they may not behave the way you expect in a given application. This may not apply in every circumstance or client library, but a good practice would be to supply a data structure that doesn’t allow repeats (see above) and serialize this into arguments when supplying them to XADD. Unique fields in and unique fields out.
Bad news
Not all client libraries and tools get it right. Relatively low-level client libraries (non-exhaustive: node_redis, hiredis) don’t do much as far as changing the output from Redis into language constructs. Other higher-level libraries do abstract the actual return of Redis into language constructs—you should check to see if your library of choice is doing this and put in an issue if it does. Some higher-level libraries got it right from the start (stackexchange.redis), so kudos are due there.
The other part that is a bit bad: if you were a very early adopter of RESP3, you might have experienced XREAD / XREADGROUP returning the RESP3 map type. Until early April, the under-development version of Redis 6 was confusingly returning maps with repeats when reading Streams. Thankfully, this was resolved and the GA version of Redis 6—the first time you should have been really using RESP3 in production—shipped with the proper return for XREAD / XREADGROUP.
The fun part
Since I’ve gone over how you’re probably wrong about Streams, let’s think for a bit about how you can leverage this heretofore-misunderstood structure.
Apply semantic meaning to order in Stream entries
So, you actually have three vectors to play with in this pattern. Imagine storing a path for vector graphics. Each Stream entry would be a unique polygon or path and the fields and values would be the coordinates. For example, take this fragment of SVG:
<polyline points="50,150 50,200 200,200 200,100">
This could be articulated as:
> XADD mySVG * 50 150 50 200 200 200 200 100
Each additional shape would be another entry on the same key. If you attempted to do something like this with a Redis Hash, you’d have only two coordinates and no order guarantee. Admittedly, you could do this with things like bitfields, but you’d lose a ton of flexibility with regards to length and coordinate size. With Streams, you could probably even do something neat with the timestamp to represent a series of shapes that appear over time.
Create a time-order set of sequenced items
This one requires a tiny hack, but could provide a lot of functionality. Imagine you are keeping a sequence of arrays-like data. Effectively, an array of arrays—in JSON you could think if it something like:
[ ["A New Hope", "The Empire Strikes Back", "Return of the Jedi"], ["The Phantom Menace", "Attack of the Clones", "Revenge of the Sith"], ["The Force Awakens", "The Last Jedi", "The Rise of Skywalker"] ]
You could articulate this as a series of Stream entries with one small nuance: you need to make sure the number of (pseudo) elements in your inner lists are not odd. If they are odd, as above, you’ll need to record that somehow—here is how I’m doing it with an empty string:
> XADD starwars * "A New Hope" "The Empire Strikes Back" "Return of the Jedi" ""
"1592427370458-0"
> XADD starwars * "The Phantom Menace" "Attack of the Clones" "Revenge of the Sith" ""
"1592427393492-0"
> XADD starwars * "The Force Awakens" "The Last Jedi" "The Rise of Skywalker" ""
"1592427414475-0"
> XREAD streams starwars 0
1# "starwars" =>
1) 1) "1592427370458-0"
2) 1) "A New Hope"
2) "The Empire Strikes Back"
3) "Return of the Jedi"
4) ""
2) 1) "1592427393492-0"
2) 1) "The Phantom Menace"
2) "Attack of the Clones"
3) "Revenge of the Sith"
4) ""
3) 1) "1592427414475-0"
2) 1) "The Force Awakens"
2) "The Last Jedi"
3) "The Rise of Skywalker"
4) ""
You gain a lot in this pattern at the (minor) expense of having to filter out any 0-length strings.
Streams as a pagination cache
A tricky thing that you see pretty often is a listing of items on a site (e-commerce, message boards, etc.). This is commonly cached but I’ve seen people have fits trying to find the best method to cache this type of data—do you cache the entire result set into something like a sorted set and paginate outward with ZRANGE, or do you store full pages at string keys? Both ways have merits and downsides.
As it turns out, Streams actually work for this. Take, for example, the e-commerce listing. You have a series of items, each with an ID. Those items are listed in a finite series of sorts that usually have a reversal (A-Z, Z-A, low to high, high to low, highest-to-lowest rating, lowest-to-highest rating, etc).
To model this type of data in a Stream, you would determine a particular “chunk” size and make that an entry. Why chunks and not full result pages at an entry? This allows for you to have different-size pages in your pagination (e.g. 10 items per page could be made of 2 chunks of 5 each, while 25 per page would be 5 chunks of 5 each). Each entry would contain fields that map to product IDs and the values would be the product data. Take a look at this simplified example with an artificially low chunk size:
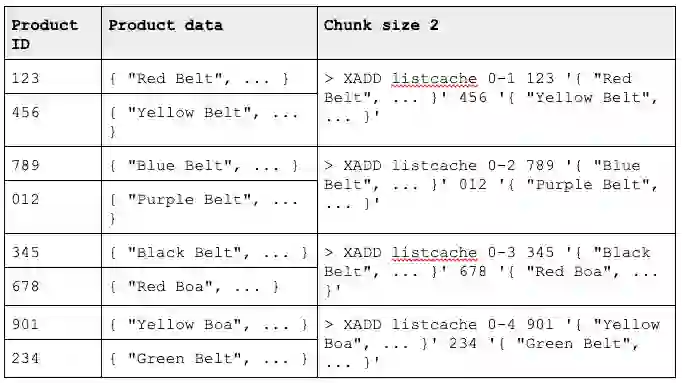
When you want to retrieve the cached values, you would run XRANGE with the COUNT argument set to the number of chunks that make up a result page for your interface. So, if you want to get the first page of four items you would run:
> XRANGE listcache - + COUNT 2
1) 1) "0-1"
2) 1) "123"
2) "{ \"Red Belt\", ... }"
3) "456"
4) "{ \"Yellow Belt\", ... }"
2) 1) "0-2"
2) 1) "789"
2) "{ \"Blue Belt\", ... }"
3) "012"
4) "{ \"Purple Belt\", ... }"
To get the second page of 4 items, you’ll need to provide a lower bound Stream ID incremented by 1, in our case, the lower bound would be 0-2.
> XRANGE listcache 0-3 + COUNT 2
1) 1) "0-3"
2) 1) "345"
2) "{ \"Black Belt\", ... }"
3) "678"
4) "{ \"Red Boa\", ... }"
2) 1) "0-4"
2) 1) "901"
2) "{ \"Yellow Boa\", ... }"
3) "234"
4) "{ \"Green Belt\", ... }"
This does provide a computational complexity advantage over Sorted Sets or Lists as XRANGE is effectively O(1) in this use, but there are a few things to keep in mind:
Like any key, you can use expiry to manage how long the Stream stays around. An example of how this can be done is in stream-row-cache.
I hope this post gives you some additional context on how Streams really work and how you can leverage these largely unknown properties of Streams in your applications.
