

Let’s say you’re working on an e-commerce website for home improvement products, like nails, screws, wood, tile, putty knives… that kind of thing. These types of stores (brick-and-mortar or online) typically sell a huge variety of products. Notably, when a person buys something from a store like this, it’s pretty common to need more of the same items at a later time—because who knows exactly how many nails you’ll need for a project?
Providing a fast and easy to use purchase history is pretty vital to delivering good user experience, but the devil lies in the details. A simplistic approach would be a reverse time-ordered list of items, but this could get frustrating after a few items. What customers really need is a way to efficiently search the purchase history of a single user.
One approach might be to keep a list of all products you’ve ever stocked, and relate a table row for each item and do a simple full-text search over the relational database system. Unfortunately the full-text search capabilities of relational databases are often lacking compared to a true full-text search engine.
Another option would be to use a true search engine working with a search index that holds the user’s name as well as product name, description, and purchase time—each as a document. This would give you true, full-text search capabilities if you constrained results to a particular user. Unfortunately, this approach can be tough to pull off, because the indexed size of the search grows rapidly as each purchase adds more and more to a single index, and every search requires querying every purchase ever by any user. Let’s evaluate how large the index would be:
| # of customers | Average # of items purchased per customers | # of Docs |
| 500,000 | 150 | 75,000,000 |
Even with a relatively modest number of users, this type of index quickly grows out of control. What happens when you have to five million users? Fifteen million users?
The pattern of usage on this feature is pretty interesting—across all users, there is probably a fairly normal distribution of usage at any given time. Without factoring in waking hours, you can assume that it won’t get surge-y. Thinking laterally, an individual user is probably touching this feature very infrequently. Indeed, in most cases, each user is not spending more than a few minutes a week on your e-commerce platform. At any given time, only a small fraction of the search index is ever being used. While a general site search should probably be available to all users at all times, the purchase-history search is inherently a logged-in-only feature.
So, what if we could have a dynamic search index for each user—when the user logs on to the site, the purchase-search history is populated from another data store and then marked to expire in a specific amount of time, just like their session? If a user manually logs out, you’re safe to delete the the search index.
This pattern requires a search engine that supports:
If you have all of those things, what does it get you? Let’s revisit our simple math, but let’s add an additional assumption: 2% of the user base is logged in at any given time.
| 2% of 500,000 | Average # of items purchased per customers | # of Docs |
| 10,000 active users | 150 | 1,500,000 |
This number of documents is far more manageable than the original strategy. Additionally, it scales based on the actual usage of your website, not cumulative purchase history. So, if your site becomes way busier (usually a good thing), then you can scale up that purchase history search with the increase in business.
Since purchase history changes infrequently, the other data store in the picture doesn’t need to be very sophisticated nor high performance—you’re accessing it only when a user logs in or when items are purchased. It could be as simple as a flat file.
Since you’re reading this on the Redis website, you might imagine that you can use this pattern with Search and Query. Indeed, Redis has several properties and features that align nicely to this use case. First, since Search and Query is a Redis feature, it inherits much of the performance of Redis itself. Like Redis, Search and Query is in-memory first, which means that writing and reading are on more equal footing, unlike disk-based systems that take much longer to alter or delete data. Quickly populating a purchase history into Search and Query is not a performance issue. Additionally, Search and Query is optimized to quickly create indexes as well as delete or expire indexes.
Digging a bit deeper, let’s see how to create your index on a per-user basis:
> FT.CREATE history:user:1234 TEMPORARY 3600 SCHEMA title TEXT description TEXT purchased NUMERIC
The only unusual thing about creating this index is the TEMPORARY argument. This tells Search and Query to make the search index ephemeral and delete it after the specified 3600 seconds (or whatever aligns with your session timeout). Any time the search index is used, adding/deleting documents or querying, resets the idle timer. Once the time expires the index will be deleted. Also, note the name of the index includes a user identifier.
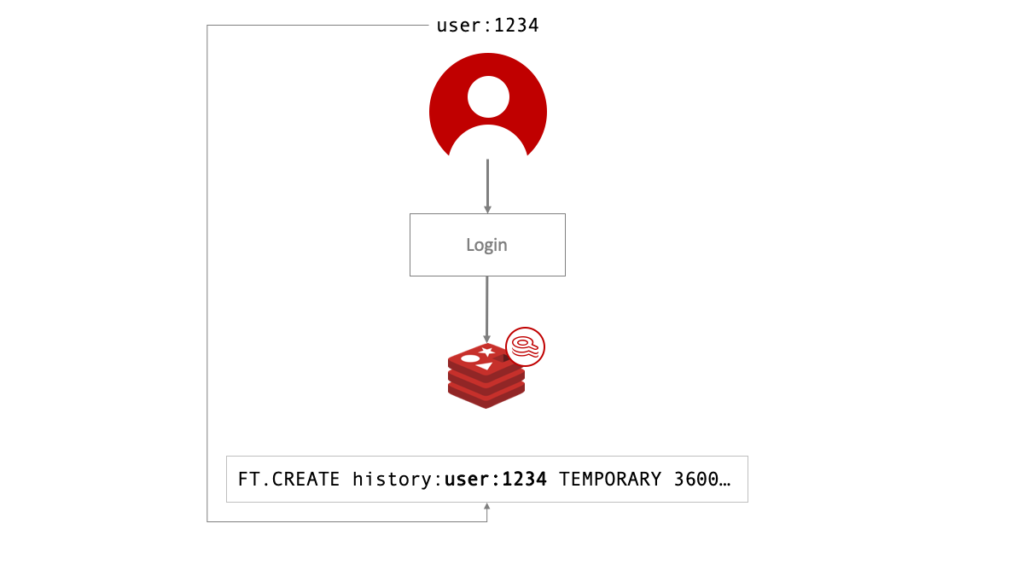
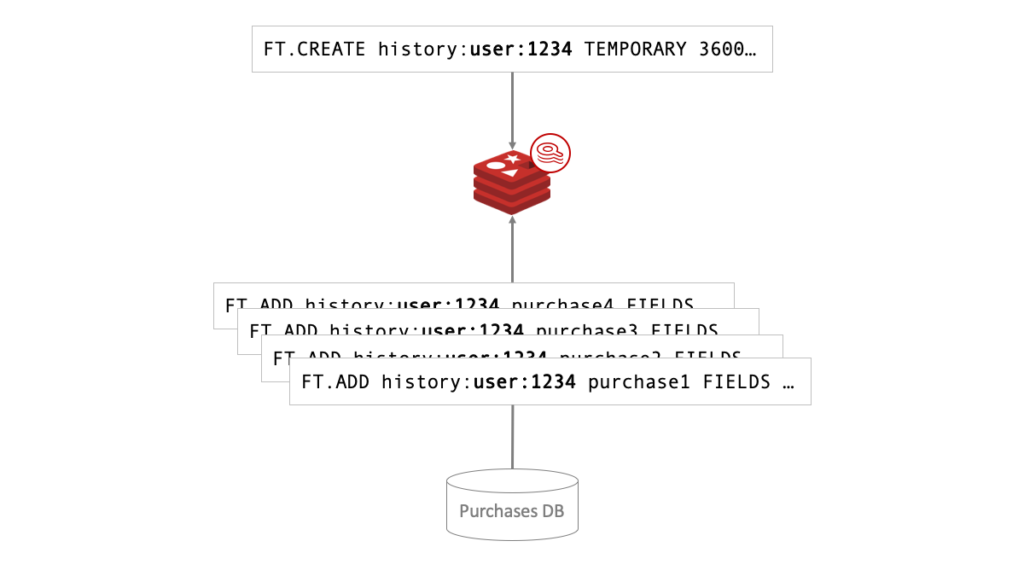
At login, the index would be populated with FT.ADD from the other data source. Nothing special needed here—Search and Query will take care of the document and keys as temporary with no other syntax. Adding the documents will be quick—in the low-single-digit-milliseconds range for most documents. This doesn’t have to be done synchronously, so as a user initially browses the site, the purchase history can be loaded in the background.
One general note about Search and Query that should be restated, especially in this multi-index context: all document names should be unique across all indexes to prevent key contention at the hash level. Finally, in some circumstances you can save space by using the NOSAVE option on FT.ADD. This will not store the document, but rather just index it, providing you with the document ID only on FT.SEARCH, though this does complicate the result retrieval process.
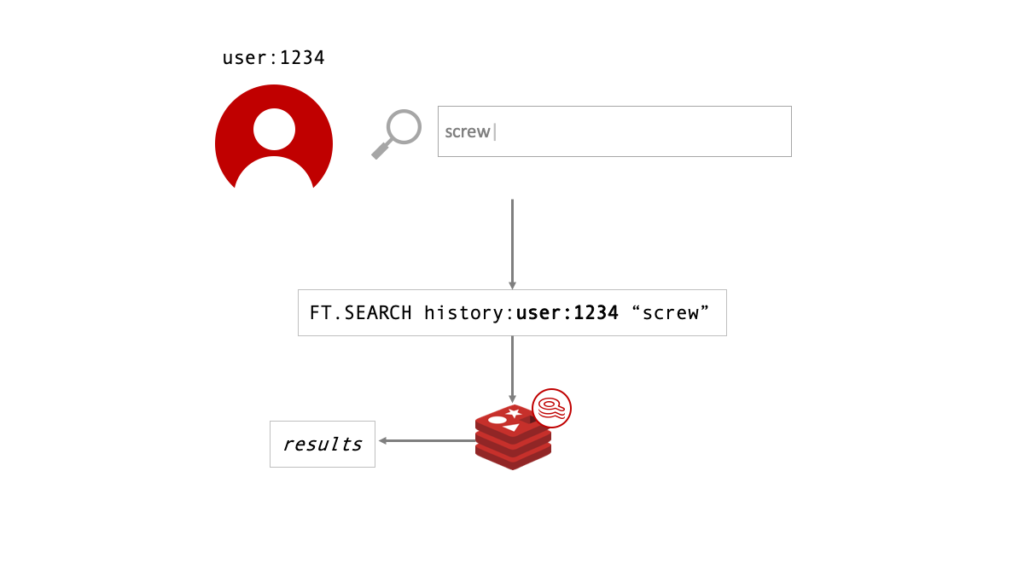
Implementing the search functionality itself is straightforward. Take the user input as the query argument to FT.SEARCH. The only difference from any implementation of Search and Query is that the index name will be derived in some way from the user identifier.
When a user explicitly logs out of the service, the FT.DROP command removes the index and documents. Strictly speaking, this is not a required operation since the TEMPORARY index will expire automatically, but using the explicit FT.DROP will free up resources a little sooner.
This particular pattern isn’t restricted to e-commerce applications. This is a viable pattern any time you have a personalized set of documents to search for a particular user. Imagine an invoice or bill search for a financial portal. Each user will have only a handful of documents specific to them, but the search experience is vital to finding specific information. In a messaging app, meanwhile, you may want to search your chat history, which again, is needed only while you’re interacting with the application and this search is specific to a single user’s chat history.
This pattern provides a way to optimize the experience for users without creating a massive, cumbersome global index that can be challenging to maintain and scale. This capability hinges on the ability to create many lightweight indexes that have expiry, and to rapidly index documents on the fly.
To get started with this pattern, download Redis at redisearch.io or take Redis Search and Query on Redis University.


