

Like many software engineers, I enjoy a good game of Dungeons & Dragons. I love powering up my character and facing increasingly more powerful foes. Doing this right requires gold and experience. And the best way to get those things is a good old-fashioned dungeon crawl.
If you need some context on D&D, this video might help. The short but overly simplified version: in D&D you explore underground complexes, fight monsters therein, and take their gold.
Unfortunately, dungeons aren’t set up for the convenience of adventurers like us. Sometimes the monster is challenging but has no treasure. Sometimes there is treasure just lying about. And sometimes the room is empty. So how do we find out where in the dungeon to get the treasure we seek?
A fun way to solve this problem is to represent a dungeon as a graph using a graph database like RedisGraph. From a data perspective, a dungeon is a collection of entities (rooms, monsters, and treasure) and their relationships. Graphs are great at modeling this sort of data. With a graph database, we can query a graph of a dungeon to find the creepy critters and the sparkling hoozits that will level up our characters.
Perhaps you’re not familiar with graphs and graph databases? Well then, join me on an adventure as we explore the what, why, and how.
Graph databases are actually pretty easy to understand. I think they’re actually easier to understand than relational databases. But if you’ve spent a lot of time in Relational Land (and many of us have, myself included) you might need to unlearn a thing or two. Just take all that relational stuff, shove it in a different part of your head, and make room to let the new ideas stream on in.
Done? OK. Let’s dive into graph databases!
A graph database contains a graph made up of nodes and edges. Explanations of graphs, nodes, and edges can get a bit abstract because, fundamentally, they’re pretty abstract ideas. So I’m going to use examples to make them a little more concrete.
Nodes are the nouns, the things, of your data. They have a label telling you what type of thing they are. They can also have attributes that provide additional information about the node. Let’s look at a couple of nodes with their labels and attributes:

Below we have two nodes. The first node has the label “room” and a single attribute telling us a bit about the room. In this case its name: “The Den of the Ogre King.” The second node has a label of “monster” and two attributes, one telling us that the monster’s name is “Ralph the Ogre King” and another that slaying him is worth 1,200 experience points.Pretty straightforward. Nodes are sort of like objects in a programming language like Java or C#. They have a type and properties.
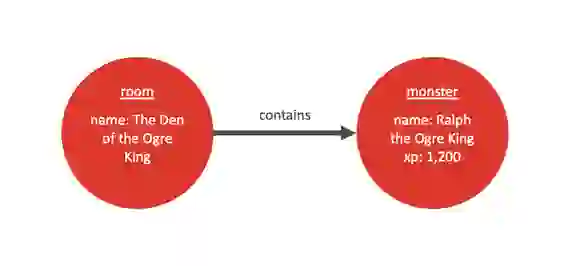
Now, let’s add in an edge and see what that does:The edge has a type of “contains” and a direction that goes from the room to the monster. Its purpose is to establish a relationship between the room and the monster. The type is the nature of that relationship and is, in many ways, like the label of a node. I like to think that edges are verbs—transitive verbs to be specific—in that they connect the nouns together: the room contains a monster. This adds a relationship between the nodes.
The direction of the edge is arbitrary. Either way, it establishes the relationship. I could have just as easily created an edge with a type of “is_contained_by” pointing the opposite direction. But then my sentence would be: the monster is contained by the room. Which is in the passive voice. And, as I was taught by my English teacher all those years ago, the passive voice is to be avoided because it’s more verbose and harder to understand.
Collectively, these nodes and edges are called a graph. The simplest (and probably least interesting) graph has no nodes at all. And without nodes, of course, it can’t have edges.
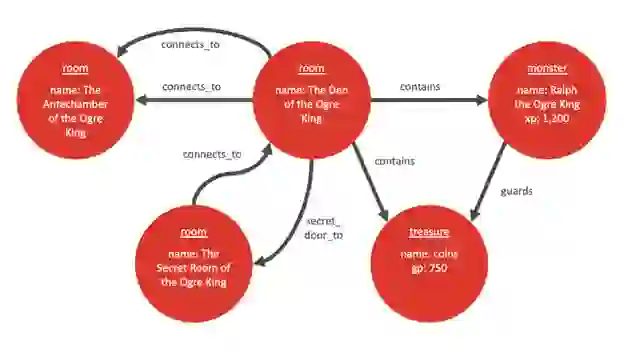
On the other hand, graphs can get quite complex. Nodes can have multiple edges going to and from them. A pair of nodes can even have multiple edges between them. And nodes can be isolated, without any edges at all!Look at that monster of a graph! It shows three rooms, a secret door, and a treasure pile. Complete with a guardian named Ralph.
I’ve been busy modeling my ridiculous example of a dungeon, all of its connected rooms, the secrets, the monsters, and the treasure. And if you were building a text-based online game like a MUD, this would be a great way to model the state of it.
But most developers aren’t building text-based games from the ‘80s. Most of us are building more practical things. What sorts of practical problems can graph databases solve? All sorts. Here are a few examples:
These are all good candidates for graph databases because they have complex relationships that would, ironically, be difficult to model with a relational database. This is one of the main strengths of graph databases: they model relationships really well.
But graph databases have another important strength: they are without schema. This can make them easier to work with once they are in production. For example:
And can you even imagine converting a one-to-many relationship to a many-to-many relationship with a relational database? With a graph database, you don’t need to care about one-to-many and many-to-many. Things just relate to each other. If they need to relate, add an edge. That’s it.
Yes. Yes you can. You might be familiar with Redis modules. Modules are extensions that you can install to extend the capabilities of Redis—often by adding new commands and data structures but sometimes quite a bit more. Redis has created several and they add all sorts of capabilities. One of them, RedisGraph, provides a data structure that is a graph database.
I don’t feel right writing a blog post without some code in it, so I’m going to show some interactions with a graph using Cypher, the query language that RedisGraph uses. I’m going to use RedisInsight to do this because it has a cool visualization tool that’s worth checking out, but you can use redis-cli if you like.
NOTE: If you do use redis-cli, be sure to begin all your Cypher queries with GRAPH.QUERY key “your cypher query here”.
> CREATE (:monster { name: 'Ralph the Ogre King', xp: 1200 })
The stuff between the parentheses is the node to be created and, after the colon, monster is the label for the node. The attributes of the node follow the label and are formatted in a very JavaScript-like way.
Now that we’ve created a monster, let’s query him:
> MATCH (m:monster) RETURN m
The MATCH here matches all nodes with the label of monster and assigns them to m. In this case, m just has one node in it. The RETURN, unsurprisingly, returns what we tell it.
This could have been even simpler. Since we have only a single node in our graph, we don’t need to check the label:
> MATCH (n) RETURN n
This query returns all nodes.
Cypher is kind of neat because its queries look sort of like a graph. Since nodes are represented as circles, when we CREATE or MATCH them, we wrap them in parentheses to suggest a circle. This idea is carried forward when we create nodes with edges.
Let’s start over with an empty graph and create a graph that has Ralph in his den:
> CREATE (:room { name: 'The Den of the Ogre King' })-[:contains]->(:monster { name: 'Ralph the Ogre King', xp: 1200 })
Here we are creating two nodes: Ralph and his den. But we are also defining a relationship between them, an edge, with what looks like an arrow with a label on it. The arrow points in the direction of the relationship and the square brackets contain the type of the relationship. In this case the room contains a monster.
We can query this structure like we did before, but now with the edges as well:
> MATCH (r:room)-[c:contains]->(m:monster) RETURN r, c, m
And, since our graph contains only two nodes and a single relationship, we could have made an even simpler query:
> MATCH (n1)-[e]->(n2) RETURN n1, e, n2
This query returns all nodes and all edges.
There’s a lot more to RedisGraph, including many more-sophisticated queries. You should dig deeper in the documentation as there’s a lot of neat stuff in there. However, here’s a useful query for us treasure seekers:
> MATCH (r:room)-[:contains]->(:monster)-[:guards]->(:treasure) RETURN r
We’ve seen the sorts of problems that graph databases can solve, and we’ve seen how to create and find nodes and edges. But how does it work internally? Well, that’s a big question that I’m not going to answer. Instead, I’d like to send you to the documentation, where you can learn about sparse adjacency matrices, matrix multiplication, and GraphBLAS.
Finally, I encourage you to more deeply explore the treasure-filled domain that is RedisGraph. Install it. Build something cool. Share it with the world. And if you build a MUD, can I play?


