



How to Manage Real-Time IoT Sensor Data in Redis
Learn more


Redis has a versatile set of data structures ranging from simple Strings all the way to powerful abstractions such as Redis Streams. The native data types can take you a long way, but there are certain use cases that may require a workaround. One example is the requirement to use secondary indexes in Redis in order to go beyond the key-based search/lookup for richer query capabilities. Though you can use Sorted Sets, Lists, and so on to get the job done, you’ll need to factor in some trade-offs.
Enter RediSearch! Available as a Redis module, RediSearch provides flexible search capabilities, thanks to a first-class secondary indexing engine. It offers powerful features such as full-text Search, auto completion, geographical indexing, and many more.
To demonstrate the power of RediSearch, this blog post offers a practical example of how to use RediSearch with Azure Cache for Redis with the help of a Go service built using the RediSearch Go client. It’s designed to give you a set of applications that let you ingest tweets in real-time and query them flexibly using RediSearch.
Specifically, you will learn how to:
As mentioned, the example service lets you consume tweets in real-time and makes them available for querying via RediSearch.
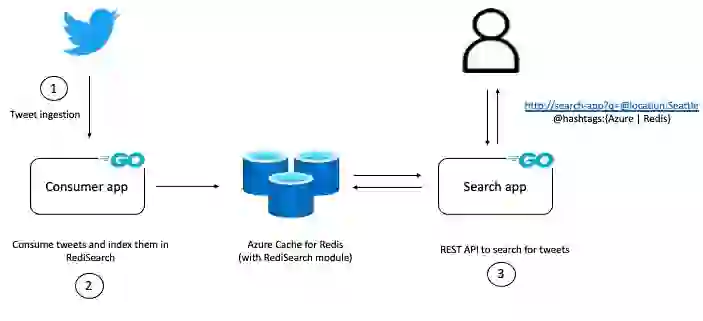
It has two components:
At this point, I am going to dive into how to get the solution up and running so that you can see it in action. However, if you’re interested in understanding how the individual components work, please refer to the Code walk through section below, and the GitHub repo for this blog: https://github.com/abhirockzz/redisearch-tweet-analysis.
Prerequisites
Start off by using this quick-start tutorial to set up a Redis Enterprise tier cache on Azure. Once you finish the set up, ensure that you have the the Redis host name and access key handy:

Both the components of our service are available as Docker containers: the Tweet indexing service and the Search API service. (If you need to build your own Docker images, please use the respective Dockerfile available on the GitHub repo.)
You will now see how convenient it is to deploy these to Azure Container Instances, which allows you to run Docker containers on-demand in a managed, serverless Azure environment.
A docker-compose.yml file defines the individual components (tweets-search and tweets-indexer). All you need to do is update it to replace the values for your Azure Redis instance as well as your Twitter developer account credentials. Here is the file in its entirety:
version: "2"
services:
tweets-search:
image: abhirockzz/redisearch-tweets-search
ports:
- 80:80
environment:
- REDIS_HOST=<azure redis host name>
- REDIS_PASSWORD=<azure redis access key>
- REDISEARCH_INDEX_NAME=tweets-index
tweets-indexer:
image: abhirockzz/redisearch-tweets-consumer
environment:
- TWITTER_CONSUMER_KEY=<twitter api consumer key>
- TWITTER_CONSUMER_SECRET_KEY=<twitter api consumer secret>
- TWITTER_ACCESS_TOKEN=<twitter api access token>
- TWITTER_ACCESS_SECRET_TOKEN=<twitter api access secret>
- REDIS_HOST=<azure redis host name>
- REDIS_PASSWORD=<azure redis access key>
- REDISEARCH_INDEX_NAME=tweets-index
docker login azure
docker context create aci aci-context
docker context use aci-context
Clone the GitHub repo:
git clone https://github.com/abhirockzz/redisearch-tweet-analysis
cd redisearch-tweet-analysis
Deploy both the service components as part of a container group:
docker compose up -p azure-redisearch-app
(Note that Docker Compose commands currently available in an ACI context start with docker compose. That is NOT the same as docker-compose with a hyphen. )
You will see an output similar to this:
[+] Running 1/3
⠿ Group azure-redisearch-app Created 8.3s ⠸ tweets-search Creating 6.3s ⠸ tweets-indexer Creating 6.3s
Wait for services to start, you can also check the Azure portal. Once both the services are up and running, you can check their respective logs:
docker logs azure-redisearch-app_tweets-indexer
docker logs azure-redisearch-app_tweets-search
If all goes well, the tweet-consumer service should have kicked off. It will read a stream of tweets and persist them to Redis.
It’s time to query the tweet data. To do so, you can access the REST API in Azure Container Instances with an IP address and a fully qualified domain name (FQDN) (read more in Container Access). To find the IP, run docker ps and check the PORTS section in the output (as shown below):
docker ps
//output
CONTAINER ID IMAGE COMMAND STATUS PORTS azure-redisearch-app_tweets-search abhirockzz/redisearch-tweets-search Running 20.197.96.54:80->80/tcazure-redisearch-app_tweets-indexer abhirockzz/redisearch-tweets-consumer Running
You can now run all sorts of queries! Before diving in, here is a quick idea of the indexed attributes that you can use in your search queries:
id - this is a the Tweet ID ( TEXT attribute)
user - the is the screen name ( TEXT attribute)
text - tweet contents ( TEXT attribute)
source - tweet source e.g. Twitter for Android, Twitter Web App, Twitter for iPhone ( TEXT attribute)
hashtags - hashtags (if any) in the tweet (available in CSV format as a TAG attribute)
location - tweet location (if available). this is a user defined location (not the exact location per se)
created - timestamp (epoch) of the tweet. this is NUMERIC field and can be used for range queries
coordinates - geographic location (longitude, latitude) if made available by the client ( GEO attribute)
(Note, I use curl in the examples below, but would highly recommend the “REST Client” for VS Code)
Set the base URL for the search service API:
export REDISEARCH_API_BASE_URL=<for example, http://20.197.96.54:80/search>
Start simple and query all the documents (using * ):
curl -i $REDISEARCH_API_BASE_URL?q=*
You will see an output similar to this:
HTTP/1.1 200 OK
Page-Size: 10
Search-Hits: 12
Date: Mon, 25 Jan 2021 13:21:52 GMT
Content-Type: text/plain; charset=utf-8
Transfer-Encoding: chunked
//JSON array of documents (omitted)
Notice the headers Page-Size and Search-Hits: these are custom headers being passed from the application, mainly to demonstrate pagination and limits. In response to our “get me all the documents” query, we found 12 results in Redis, but the JSON body returned 10 entries. This is because of the default behavior of the RediSearch Go API, which you can change using different query parameter, such as:
curl -i "$REDISEARCH_API_BASE_URL?q=*&offset_limit=0,100"
offset_limit=0,100 will return up to 100 documents ( limit ) starting with the first one ( offset = 0).
Or, for example, search for tweets sent from an iPhone:
curl -i "$REDISEARCH_API_BASE_URL?q=@source:iphone"
You may not always want all the attributes in the query result. For example, this is how to just get back the user (Twitter screen name) and the tweet text:
curl -i "$REDISEARCH_API_BASE_URL?q=@location:india&fields=user,text"
How about a query on the user name (e.g. starting with jo):
curl -i "$REDISEARCH_API_BASE_URL?q=@user:jo*"
You can also use a combination of attributes in the query:
bash curl -i $REDISEARCH_API_BASE_URL?q=@location:India @source:android
How about we look for tweets with specific hashtags? It is possible to use multiple hashtags (separated by |)?
curl -i "$REDISEARCH_API_BASE_URL?q=@hashtags:\{potus|cov*\}"
Want to find out how many tweets with the biden hashtag were created recently? Use a range query:
curl -i "$REDISEARCH_API_BASE_URL?q=@hashtags:{biden} @created:[1611556920000000000 1711556930000000000]"
If you were lucky to grab some coordinates info on the tweets, you can try extracting them and then query on coordinates attribute:
curl -i "$REDISEARCH_API_BASE_URL?q=*&fields=coordinates"
curl -i "$REDISEARCH_API_BASE_URL?q=@coordinates:[-122.41 37.77 10 km]"
These are just a few examples. Feel free to experiment further and try out other queries. This section in the RediSearch documentation might come in handy!
Important: After you finish, don’t forget to stop the services and the respective containers in Azure Container Instances:
docker compose down -p azure-redisearch-app
Use the Azure Portal to delete the Azure Redis instance that you had created.
This section provides a high-level overview of the code for the individual components. This should make it easier to navigate the source code in the GitHub repo.
Tweets consumer/indexer:
go-twitter library has been used to interact with Twitter.
It authenticates to the Twitter Streaming API:
config := oauth1.NewConfig(GetEnvOrFail(consumerKeyEnvVar), GetEnvOrFail(consumerSecretKeyEnvVar))
token := oauth1.NewToken(GetEnvOrFail(accessTokenEnvVar), GetEnvOrFail(accessSecretEnvVar))
httpClient := config.Client(oauth1.NoContext, token)
client := twitter.NewClient(httpClient)
And listens to a stream of tweets in a separate goroutine:
demux := twitter.NewSwitchDemux()
demux.Tweet = func(tweet *twitter.Tweet) {
if !tweet.PossiblySensitive {
go index.AddData(tweetToMap(tweet))
time.Sleep(3 * time.Second)
}
}
go func() {
for tweet := range stream.Messages {
demux.Handle(tweet)
}
}()
Notice the go index.AddData(tweetToMap(tweet))—this is where the indexing component is invoked. It connects to Azure Cache for Redis:
host := GetEnvOrFail(redisHost)
password := GetEnvOrFail(redisPassword)
indexName = GetEnvOrFail(indexNameEnvVar)
pool = &redis.Pool{Dial: func() (redis.Conn, error) {
return redis.Dial("tcp", host, redis.DialPassword(password), redis.DialUseTLS(true), redis.DialTLSConfig(&tls.Config{MinVersion: tls}
}
It then drops the index (and the existing documents as well) before re-creating it:
rsClient := redisearch.NewClientFromPool(pool, indexName)
err := rsClient.DropIndex(true)
schema := redisearch.NewSchema(redisearch.DefaultOptions).
AddField(redisearch.NewTextFieldOptions("id", redisearch.TextFieldOptions{})).
AddField(redisearch.NewTextFieldOptions("user", redisearch.TextFieldOptions{})).
AddField(redisearch.NewTextFieldOptions("text", redisearch.TextFieldOptions{})).
AddField(redisearch.NewTextFieldOptions("source", redisearch.TextFieldOptions{})).
//tags are comma-separated by default
AddField(redisearch.NewTagFieldOptions("hashtags", redisearch.TagFieldOptions{})).
AddField(redisearch.NewTextFieldOptions("location", redisearch.TextFieldOptions{})).
AddField(redisearch.NewNumericFieldOptions("created", redisearch.NumericFieldOptions{Sortable: true})).
AddField(redisearch.NewGeoFieldOptions("coordinates", redisearch.GeoFieldOptions{}))
indexDefinition := redisearch.NewIndexDefinition().AddPrefix(indexDefinitionHashPrefix)
err = rsClient.CreateIndexWithIndexDefinition(schema, indexDefinition)
The index and its associated documents are dropped to allow you to start with a clean state, which makes it easier to experiment/demo. You can choose to comment out this part if you wish.
Information for each tweet is stored in a HASH (named tweet:<tweet ID>) using the HSET operation:
func AddData(tweetData map[string]interface{}) {
conn := pool.Get()
hashName := fmt.Sprintf("tweet:%s", tweetData["id"])
val := redis.Args{hashName}.AddFlat(tweetData)
_, err := conn.Do("HSET", val...)
}
Tweets search exposes a REST API to query RediSearch. All the options (including query, etc.) are passed in the form of query parameters. For example, http://localhost:8080/search?q=@source:iphone. It extracts the required query parameters:
qParams, err := url.ParseQuery(req.URL.RawQuery)
if err != nil {
log.Println("invalid query params")
http.Error(rw, err.Error(), http.StatusBadRequest)
return
}
searchQuery := qParams.Get(queryParamQuery)
query := redisearch.NewQuery(searchQuery)
The q parameter is mandatory. However, you can also use the following parameters for search:
For example:
http://localhost:8080/search?q=@source:Web&fields=user,source&offset_limit=5,100
fields := qParams.Get(queryParamFields)
offsetAndLimit := qParams.Get(queryParamOffsetLimit)
Finally, the results are iterated over and passed back as JSON (array of documents):
docs, total, err := rsClient.Search(query)
response := []map[string]interface{}{}
for _, doc := range docs {
response = append(response, doc.Properties)
}
rw.Header().Add(responseHeaderSearchHits, strconv.Itoa(total))
err = json.NewEncoder(rw).Encode(response)
That’s all for this section!
Redis Enterprise is available as a native service on Azure in the form of two new tiers for Azure Cache for Redis which are operated and supported by Microsoft and Redis. This service gives developers access to a rich set of Redis Enterprise features, including modules like RediSearch. For more information, see these resources:
This end-to-end application demonstrates how to work with indexes, ingest real-time data to create documents (tweet information) which are indexed by RediSearch engine and then use the versatile query syntax to extract insights on those tweets.
Want to understand what happens behind the scenes when you search for a topic on the Redis documentation? Check out this blog post to learn how Redis site incorporated full-text search with RediSearch! Or, perhaps you’re interested in exploring how to use RediSearch in a serverless application?
If you’re still getting started, visit the RediSearch Quick Start page.
If you want to learn more about the enterprise capabilities in Azure Cache for Redis, you can check out the following resources:

