



Schemaless Databases: Pros and Cons
Learn more


Related E-Book download: The Importance of In-Memory NoSQL Databases
Running a Redis SQL query doesn’t have to be difficult. I actually raised this point a few years ago when speaking to a friend who manages data warehousing solutions at a retail company. We began talking about Redis’ queries once he explained a problem that he was facing.
“We have a pain point with our data warehousing solutions. We have use cases where we need to record data and perform analytical operations in real-time. However, sometimes it takes minutes to get the results. Can Redis help here? Keep in mind that we can’t rip and replace our SQL-based solution all at once. We can only take a baby step at a time.”
Now, if you’re in the same situation as my friend, we have good news for you. There are a number of ways you can run a Redis query and introduce Redis into your architecture without disrupting your current SQL-based solution.
Let’s explore how you can do this. But before we go any further, we have a Redis Hackathon contestant who created his own app that allows you to query data in Redis with SQL.
Watch the video below.

It’s quite straightforward to map your table to Redis data structures. The most useful data structures to follow are:
One way that you can do this is by storing every row as a Hash with a key that’s based on the table’s primary key and have the key stored in a Set or a Sorted Set.
Figure 1 shows an example of how you could map a table into Redis data structures. In this example, we have a table called Products. Every row is mapped to a Hash data structure.
The row with primary id, 10001 will go in as a Hash with the key: product:10001. We have two Sorted Sets in this example: the first to iterate through the data set by the primary key and the second to query based on price.
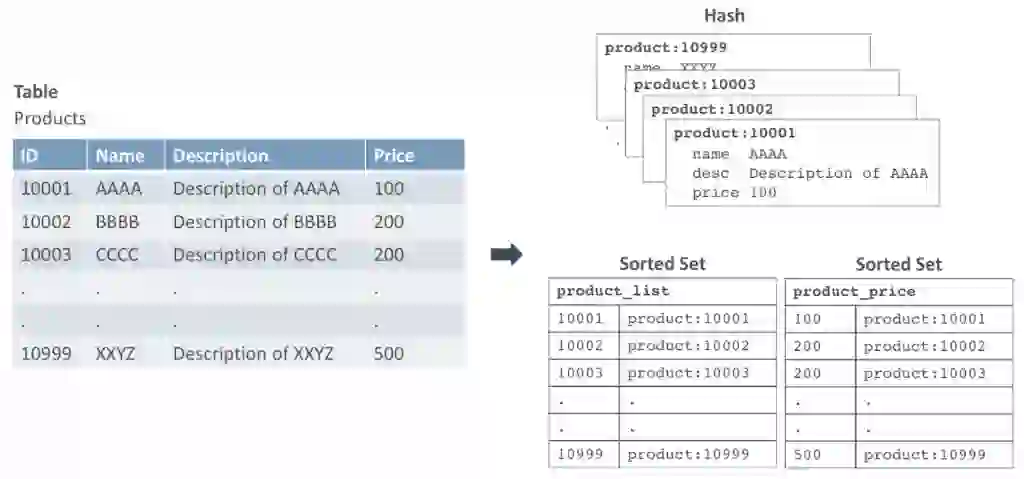
Figure 1. Mapping a table to Redis data structures
With this option, you need to make changes to your code to use Redis queries instead of SQL commands. Below are some examples of SQL and Redis equivalent commands:
A. Insert data
SQL: insert into Products (id, name, description, price) values = (10200, “ZXYW”,“Description for ZXYW”, 300);
Redis: MULTI HMSET product:10200 name ZXYW desc “Description for ZXYW” price 300 ZADD product_list 10200 product:10200 ZADD product_price 300 product:10200 EXEC
B. Query by product id
SQL: select * from Products where id = 10200
Redis: HGETALL product:10200
C. Query by price
SQL: select * from Product where price < 300
Redis: ZRANGEBYSCORE product_price 0 300
This returns the keys: product:10001, product:10002, product:10003. Now run HGETALL for each key.
HGETALL product:10001 HGETALL product:10002 HGETALL product:10003
Now, if you want to maintain the SQL interface in your solutions and only change the underlying data store to Redis to make it faster, then you can do so by using Apache Spark and Spark-Redis library.
Spark-Redis library allows you to use the DataFrame APIs to store and access Redis data. In other words, you can insert, update and query data using SQL commands, but the data is internally mapped to Redis data structures.
First, you need to download spark-redis and build the library to get the jar file. For example, with spark-redis 2.3.1, you get spark-redis-2.3.1-SNAPSHOT-jar-with- dependencies.jar.
You then next have to make sure that you have your Redis instance running. In our example, we’ll run Redis on localhost and the default port 6379.
You can also run your queries on Apache Spark engine. Here’s an example of how you can do this:
$ spark-shell --jars spark-redis-2.3.1-SNAPSHOT-jar-with-dependencies.jar
scala> import org.apache.spark.sql.SparkSession
scala> val spark = SparkSession
.builder()
.appName("redis-sql")
.master("local[*]")
.config("spark.redis.host","localhost")
.config("spark.redis.port","6379").getOrCreate()
scala> import spark.sql
scala> import spark.implicits._
scala> sql("create table if not exists products(id string, name string, description string, price int) using org.apache.spark.sql.redis options (table 'product')")
scala> sql("insert into products values = ('10200','ZXYW','Description of ZXYW', 300)")
scala> val results = sql("select * from products")
scala> results.show()
+-----+----+-------------------+-----+
| id|name| description|price|
+-----+----+-------------------+-----+
|10200|ZXYW|Description of ZXYW| 300|
+-----+----+-------------------+-----+
Now you can also use your Redis client to access this data as Redis data structures:
127.0.0.1:6379> keys product* 1) "product:2e3f8611dbe94a588706a2aaea547caa"
A more effective approach would be to use the scan command because it allows you to paginate as you navigate through the data.
127.0.0.1:6379> scan 0 match product* 1) "3" 2) 1) "product:2e3f8611dbe94a588706a2aaea547caa" 127.0.0.1:6379> hgetall product:2e3f8611dbe94a588706a2aaea547caa 1) "name" 2) "ZXYW" 3) "price" 4) "300" 5) "description" 6) "Description of ZXYW" 7) "id" 8) "10200"
And there we have it – two simple ways you can run a Redis SQL query without disruption. Going one step further, you may want to find out Why Your SQL Server Needs Redis in our new whitepaper.
But regarding real-time data with Redis, this is only one of many ways you can use it to provide real-time experiences.
If you want to discover how Redis can guarantee you real-time data transmission, then make sure to contact us.

