Search-engine databases are specialized software tools or components that help users search and retrieve data stored within a database in a high quality, rapid, and cost-effective manner.. These databases are highly optimized for keyword queries and typically offer specialized methods such as full-text search, complex search expressions, and ranking of search results.
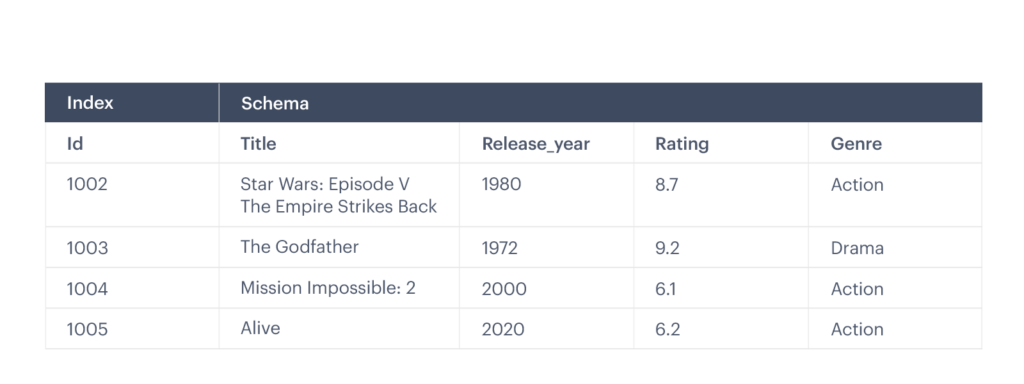
Redis Enterprise provides a real-time search engine that enables you to query your Redis data to answer a wide variety of complex questions. Use it as a secondary index for datasets hosted in Redis, as a fast text-search or auto-complete engine, as a vector database for similarity search, or as an engine for light-speed aggregations and faceted queries. Rich with features, Redis Search and Query supports capabilities for search and filtering such as geo-spatial queries, retrieving only IDs (instead of whole documents), and custom document scoring. Aggregations can combine map, filter, and reduce/groupby operations in custom pipelines that run across millions of elements in an instant. Redis Search and Query also supports auto-completion with fuzzy prefix matching, and atomic real-time insertion of new documents to a search index.


