

The newly introduced RediSearch 1.6 adds some important new functionality, including aliasing, a low-level API, and improved query validation, as well as making Fork garbage collection the module’s default. Even more important, though, the original code in RediSearch 1.6 has been refactored to significantly boost performance. The improved performance leads to a better user experience as applications can be more reactive than ever with search.
(For more on the new features in RediSearch 1.6, see our blog post on Announcing RediSearch Version 1.6.)
Just how big is the performance bump in RediSearch 1.6? That’s what this post is all about, and we’ll get to the results in a moment. But in order to fully understand the performance issues, we needed a way to properly compare database search speed.
To compare RediSearch version 1.6 against the previous 1.4 release, we created a full-text search benchmark. FTSB (licensed under MIT) was designed specifically to help developers, system architects, and DevOps practitioners find the best search engine for their workloads. It allows us to generate datasets and then benchmark read and write performance on common search queries. It supports two data sets with different characteristics:
To achieve reproducible results, the data to be inserted and the queries to be run are pre-generated, and native Go clients are used wherever possible to connect to each database. In order to design a common benchmarking suite, all latency results include the network round-trip time (RTT) to measure duration to and from the client, so that we can properly compare additional databases.
We encourage you to run these benchmarks for yourself to independently verify the results on your hardware and datasets of choice. More importantly, we’re looking for feedback and extension requests to the tool with further use cases (e.g. ecommerce, JSON data, geodata, etc.) and problem domains. If you are the developer of a full-text search engine and want to include your database in the FTSB, feel free to open an issue or a pull request to add it.
We ran the performance benchmarks on Amazon Web Services instances, provisioned through our benchmark testing infrastructure. Both the benchmarking client and database servers were running on separate c5.24xlarge instances. The tests were executed on a single node Redis Enterprise cluster setup, version 5.4.10-22, with data distributed across 10 master shards.
In addition to this primary benchmark/performance analysis scenario, we also enabled running baseline benchmarks on network, memory, CPU, and I/O, in order to understand the underlying network and virtual machine characteristics. We represent our benchmarking infrastructure as code so that it is easily replicable and stable.
The table below displays the size of the datasets we used in this benchmark. It also shows the overall indexing rate for each dataset. You can see that RediSearch 1.6 did not degrade performance on ingestion:

FSTB currently supports three full-text search queries, as shown in the chart below (remember that the latency results include RTT). Note that we plan to extend this benchmark suite with a more diversified set of read queries.
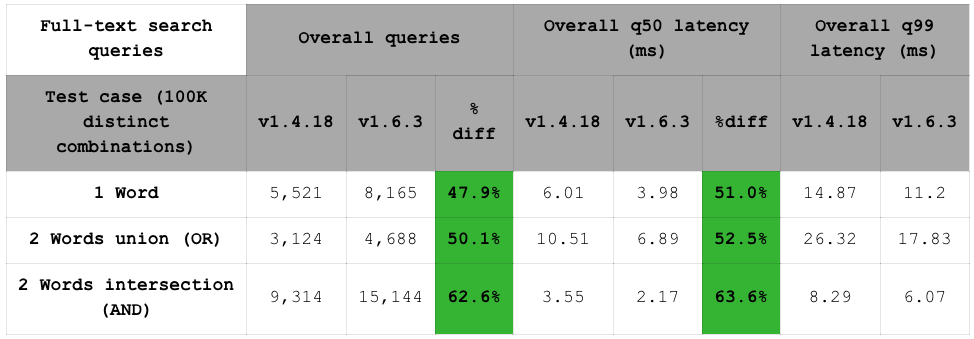
We can observe in the table above that RediSearch 1.6’s improved q99 makes it more predictable, with fewer latency peaks.The chart below shows that compared to RediSearch 1.4, RediSearch 1.6 increases throughput by 48% to 63%.

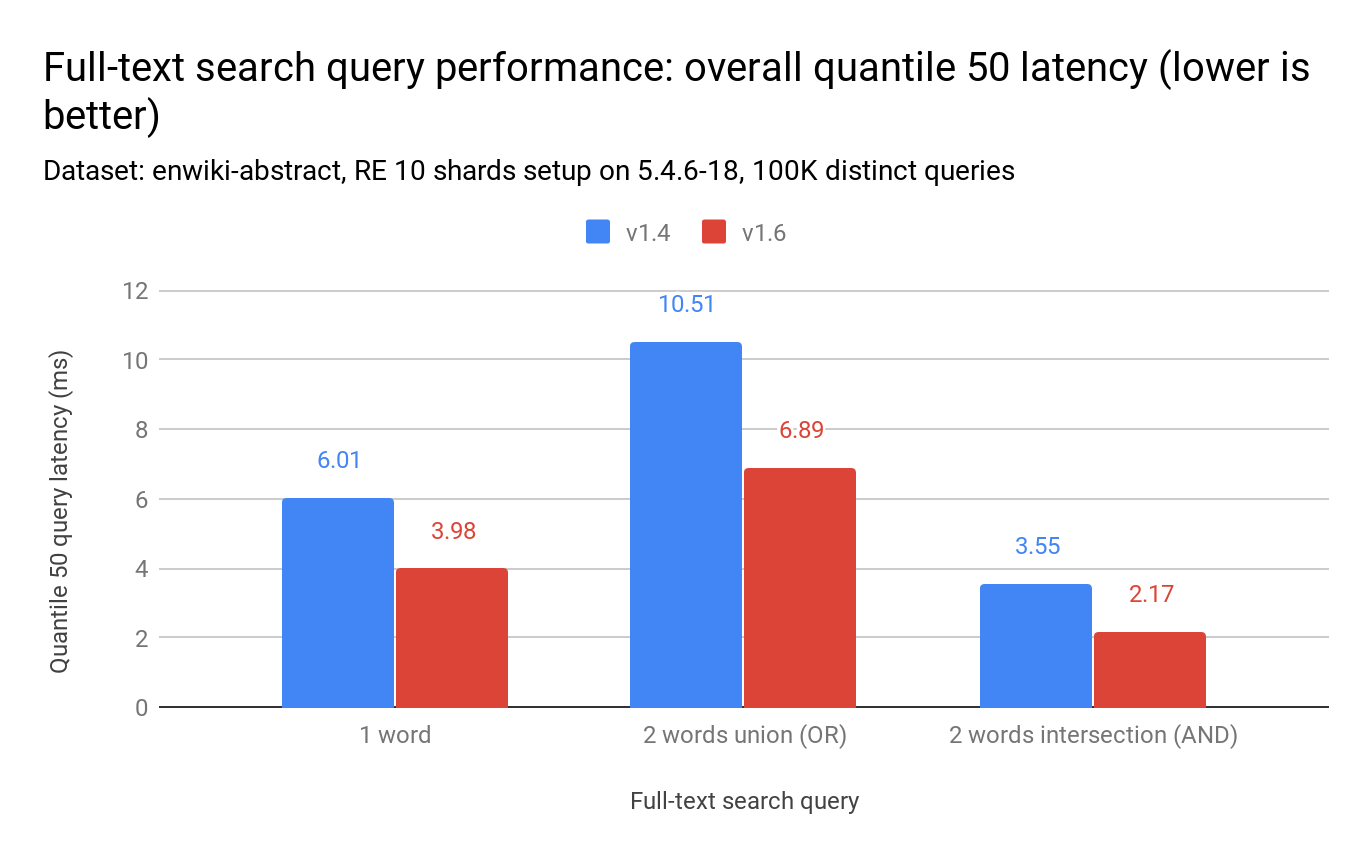
Similarly, the latency (q50) drops by 51% to 64%.
In addition to the simple search queries, we also added a set of aggregation queries. The full details of what each query does can be found in our benchmark repository (again, remember that the latency results include RTT):
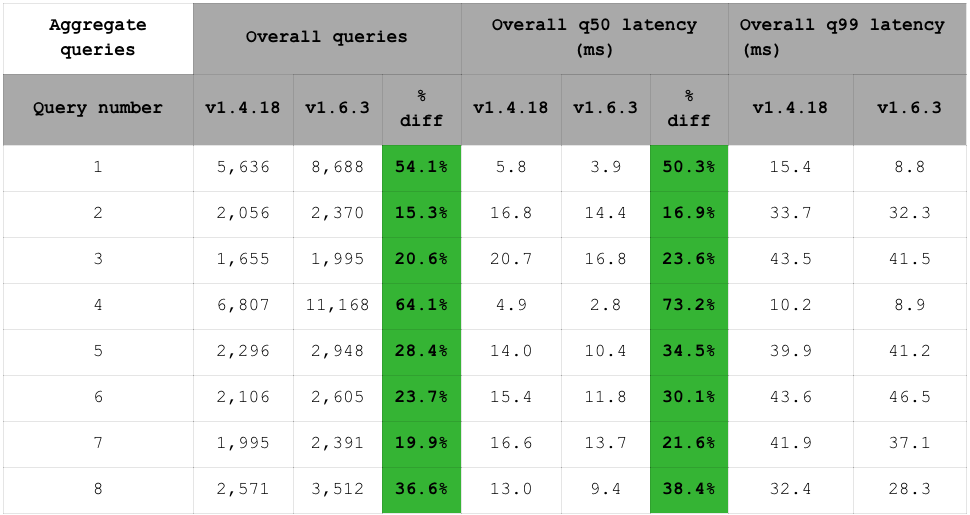
Here too, RediSearch 1.6 improves performance compared to RediSearch 1.4. The throughput increases by 15% to 64%:
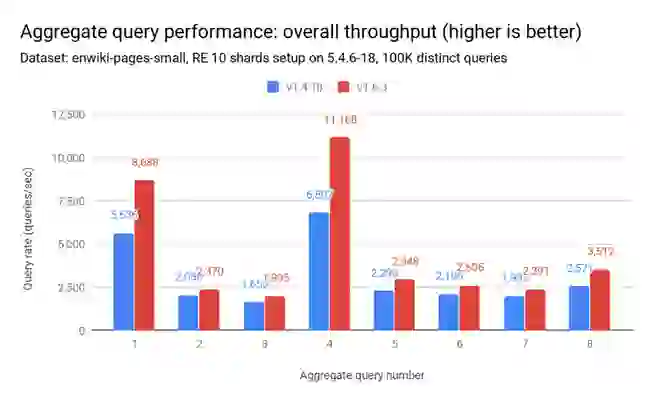
Similarly, the latency (q50) decreases by 17% to 73%:

Put it all together, and you can see that RediSearch 1.6 brings significant performance advantages compared to version 1.4. Specifically, RediSearch 1.6 increased simple full-text search throughput by up to 63% while cutting latency (q50) by up to 64%. For aggregate queries, throughput increased from 15% to 64%.
Almost as important, the introduction of full-text search benchmarking helped us to constantly monitor the performance between different versions of RediSearch and it has proven to be of extreme value in eliminating performance bottlenecks and hardening our solution.



