

In Redis Enterprise 5.0, we introduced support for the Open Source (OSS) cluster API, which allows a Redis Enterprise cluster to scale infinitely and linearly by adding shards and nodes. This post describes the first of our linear scaling benchmark tests and how Redis Enterprise works with the OSS cluster API and demonstrates infinite linear performance scalability.
Over the course of the last few months, we conducted tests that included additional benchmarking—n-shard database on a k-node Redis Enterprise cluster, as noted below:
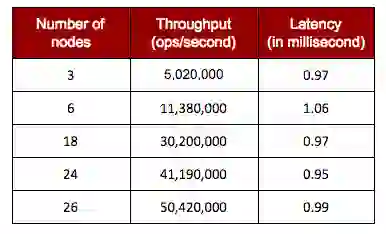
Table 1: Redis Enterprise scale linearly while delivering sub-millisecond performance
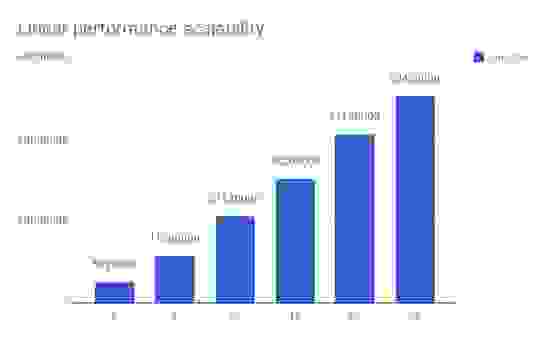
Figure 1: Cluster throughput (@ 1 msec latency)
This demonstrates that as throughput increases, there is a linear proportional increase in nodes, and Redis Enterprise is able to consistently deliver sub-millisecond latency across all data sizes and workloads. The details behind this analysis, as well as a complete write-up of the benchmark configuration, is available in this whitepaper.
According to Wikipedia, a scalable database is one that can be upgraded to process more transactions by adding new processors and storage, and which can be upgraded easily and transparently without shutting it down. A database can scale out (by adding node(s) to the cluster, rebalancing, and then resharding your database) or scale up (by adding shards to your database without adding nodes to your cluster). Redis Enterprise is optimized to scale both out and up, simply by the virtue that it’s not bound to disk.
“Linear scaling” (when scaling out) means sequentially scaling your database by adding resources (in Redis terms, “resources” refers to nodes and shards) that correlate to the increased throughput. True linear scalability means that the amount of resources increases at the same proportion as your database throughput, and in a deterministic manner. For example, increasing your cluster resources by 50% will translate to 50% throughput increases.
Understanding the scalability of multi-node systems is crucial for resource planning; it’s important to know exactly how adding nodes and shards will impact performance. If a database can scale linearly, it minimizes operational overhead and allows you to grow your business without having to worry about size limits or performance bottlenecks in your database. However, very often there is an overhead associated with scaling out, which means when you increase your capacity by N, your database throughput often increases by a factor that’s less (or much less) than N.
A database delivers:
The simple answer is NO!
There have been many benchmarks and blogs published by other database vendors on their ability to scale, but truly, the results show that Redis Enterprise outperforms its NoSQL counterparts.
The chart below is the outcome of a benchmark that one of the other NoSQL vendors performed. It compares NoSQL databases such as Apache Cassandra, Hbase, MongoDB, and Couchbase.
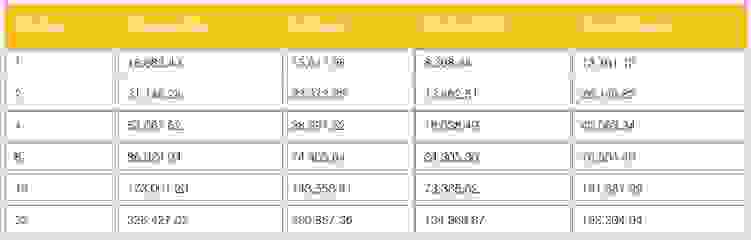
Table 2: Nodes and throughput by vendor
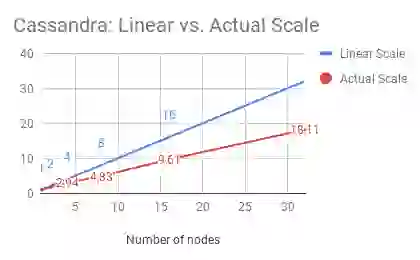
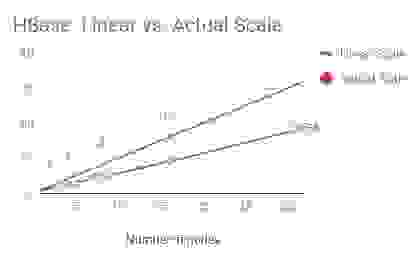
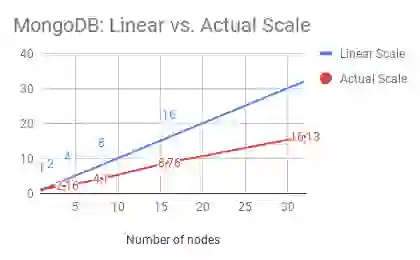
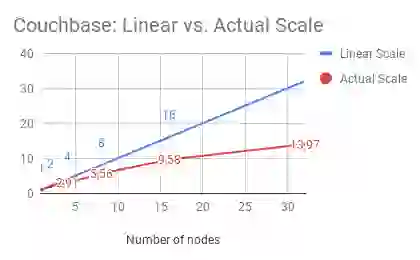
As is obvious from the charts, all of these vendors deliver sub-linear scale. For instance, if we analyze Cassandra’s throughput by node, Cassandra can process ~18,700 ops/second (rounding up) with 1 node. Then, at 32 nodes, it should have been able to process ~600,000 ops/second. However, as illustrated above, it can only process about ~330,000 operations/second—only 55% of what a truly linearly scaling database should be able to process.
The same math and conclusion hold good for all other vendors in this table.
The fact that these databases are measuring tens of thousands of requests per second as their best-case scenario is rather appalling. Modern-day applications such as eCommerce, social networking, online gaming, messaging and collaboration, the Internet of Things, and many others need to be able to handle millions of operations per second. These databases are clearly not built for such volumes while delivering lower TCO.
With its latest benchmark, Redis Enterprise has proven its ability to process millions of operations per second, even when using its most basic configuration. As demonstrated in the chart below, Redis Enterprise simply outperforms the other databases and delivers super-linear scale without any compromise to performance!

Table 3: Redis Enterprise – Optimal vs. Actual Throughput by Node
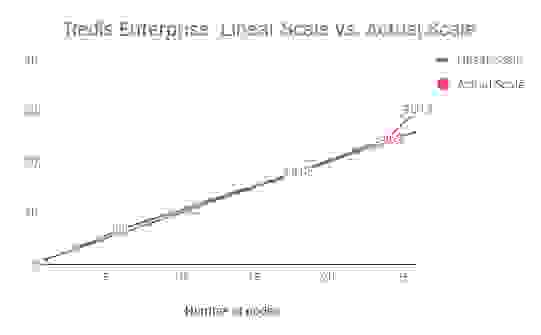
This new benchmark demonstrates Redis Enterprises’ ability to achieve true linear scalability, while delivering the predictable and fast performance with the most efficient use of your resources, helping you build scalable modern applications cost-effectively.


