

As you may know, Running Redis with persistence storage on AWS has been a challenge for users. Local storage lacks data durability, and standard EBS is perceived to be slow and unpredictable. A recent discussion amongst the Redis community suggested that users change the default Redis configuration to AOF with “fsync every second” for better data durability than you can get with today’s default snapshotting policy. As many Redis users run on AWS, one of the arguments against changing the configuration is the perceived slowness of EBS, and the fact that AOF is much more demanding than snapshotting with respect to storage access. As a provider of the Redis Cloud, we decided to find out whether EBS really slows down Redis when used over various AWS platforms. Redis Data Persistence: Redis’ AOF and Snapshotting persistent storage mechanisms are very efficient, as they only use sequential writes with no seek time. Because of this, Redis can run pretty well with data-persistence even on non-SSD hardware. That being said, slow storage devices can still be very painful for Redis. We see this when the AOF “fsync every second” policy blocks an entire Redis operation due to slow disk I/O. In addition, background saving for point-in-time snapshots or AOF rewrites takes longer, which results in more memory being used for copy-on-write, and less memory being available for your app. Testing Redis with and without Persistent Storage: We conducted our latest benchmark to understand how each typical Redis configuration on AWS performs with and without persistent storage. We tested AOF with the “fsync every second” policy, as we believe this is the most common data-persistence configuration that nicely balances performance and data durability. In fact, over 90% of our Redis users who enable data-persistence use AOF with “fsync every second.” Although it is a common Redis configuration, we didn’t test a setup in which a master node serves the entire data from RAM, leaving the slave node to deal with data persistence. This configuration may result in issues like replication bottlenecks between master and slave, which are not directly related to the storage bottlenecks we were testing for. And, we’re leaving the effect of Redis fork, AOF rewrite and snapshot operations for our next posts, so stay tuned! Benchmark test results Here’s what we found out when trying to compare how each platform runs with and without data-persistence. Throughput 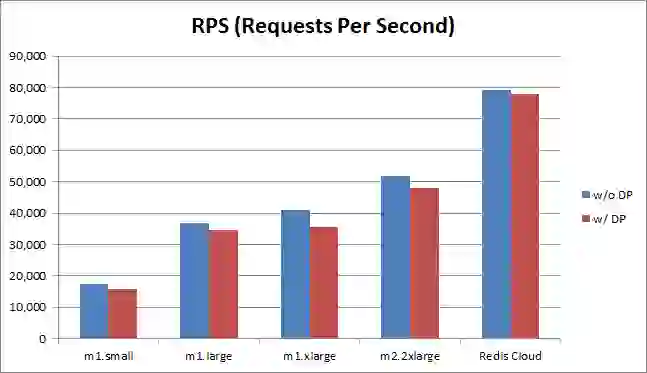
All the platforms ran a bit faster without data-persistence (w/o DP), but the difference was very small: 15% with m1.xlarge instance, equal or less than 8% for other instances, and about 1% with the Redis Cloud platform. Note: By default, Redis Cloud uses a raided EBS configuration for each of its cluster nodes (see more setup details at the end of this post), but we used a non-raided configuration for all the other platforms in this benchmark. It is therefore safe to assume that a more optimal EBS configuration can reduce performance degradation. Latency 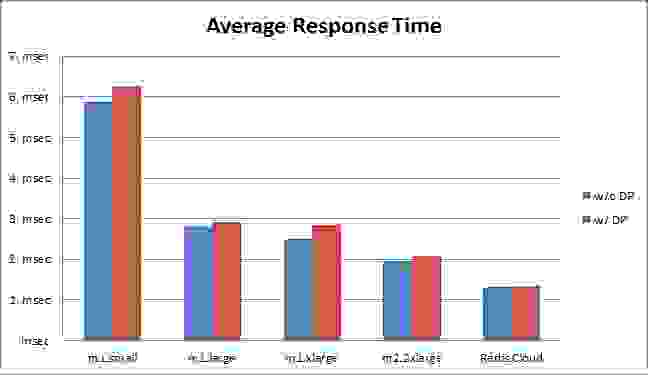
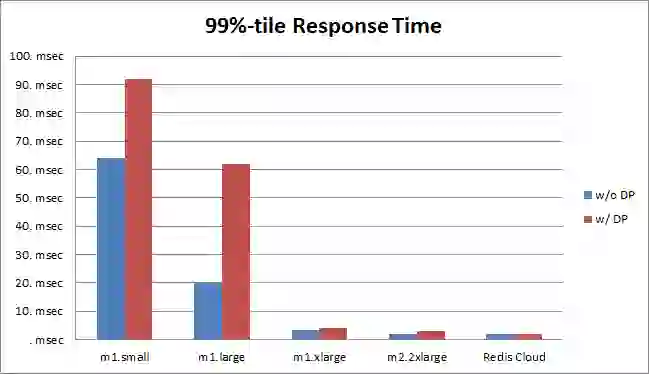
Average response time was 13% higher with data-persistence on the m1.xlarge instance and less than 8% higher in all other instances. Again, due to the optimal EBS configuration of the Redis Cloud, the average response time with data-persistence was higher by only 2%. Significant latency gaps were seen in 99%-tile response time with m1.small and m1.large instances, mainly because these instances are much more likely to be shared on a physical server than large instances like m2.2xlarge and m2.4.xlarge, as nicely explained by Adrian Cockcroft here. On the other hand, very small higher latencies were seen with m1.xlarge and m2.2xlarge instances, and an equal response-time was seen with the Redis Cloud. Note: Our response time measurement takes into account the network round-trip, the Redis/Memcached processing time, and the time it takes our memtier_benchmark tool to parse the result. Should AOF be the default Redis configuration? We think so. This benchmark clearly shows that running Redis over various AWS platforms using AOF with a standard, non-raided EBS configuration doesn’t significantly affect Redis’ performance under normal conditions. If we take into account that Redis professionals typically tune their redis.conf files carefully before using any data persistence method, and that newbies usually don’t generate loads as large as the ones we used in this benchmark, it is safe to assume that this performance difference can be almost neglected in real-life scenarios. Why does Redis Cloud perform much better ?
Behind the scenes, we monitor each and every Redis command and constantly compare its response time to what should be an optimal value. This architecture lets our customers run on the strongest instances and enjoy the highest performance, regardless of their dataset size (including small-to-medium). And with Garantia Data, they can do this while paying only for their actual GB used on an hourly basis — so they get the best of both worlds. Benchmark test setup For those who want to know more details about our benchmark, here are the resources we used:
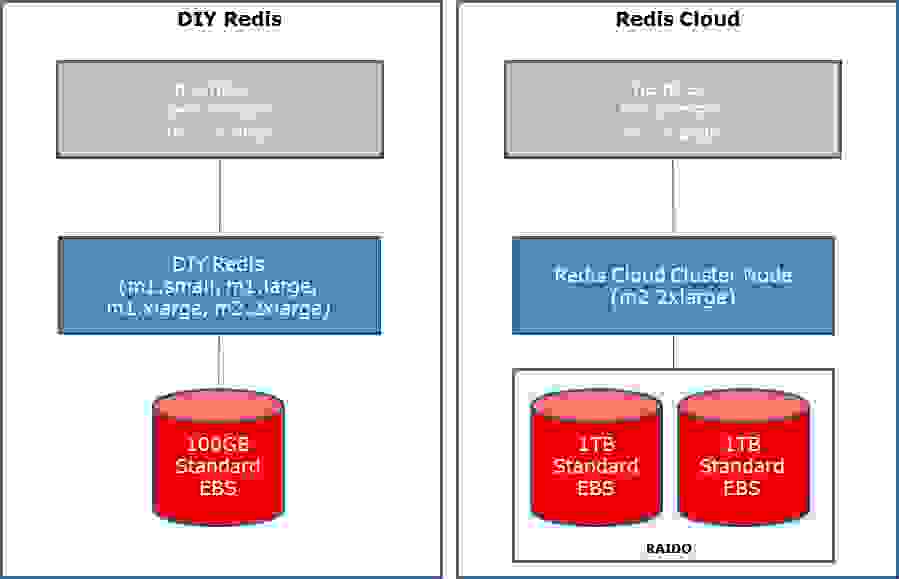 For each tested platform we ran 2 tests:
For each tested platform we ran 2 tests:
We ran each test three times on each configuration, and calculated the average results using the following parameters:
Our dataset sizes included:


