


TL;DR: We’ve utilized the powerful Redis Modules API to build a super-fast and feature-rich search engine inside Redis, from scratch — with its own custom data types and algorithms.
Earlier this year, Salvatore Sanfilippo, the author of Redis, started developing a way for developers to extend Redis with new capabilities: the Redis Modules API. This API allows users to write code that adds new commands and data types to Redis, in native C. At Redis, we quickly began experimenting with modules to take Redis to new places it’s never gone before.
One of the super exciting, but less trivial, cases that we explored was building a search engine. Redis is already used for search by many users via client libraries (we’ve even published a search client library ourselves). However, we knew the power of Redis Modules would enable search features and performance that these libraries cannot offer.
So we started working on an interesting search engine implementation – built from scratch in C and using Redis as a framework. The result, RediSearch, is now available as an open source project.
Its key features include:
Let’s look at some of the key concepts of RediSearch using this example with the redis-cli tool:
The first step of using RediSearch is to create the index definition, which tells RediSearch how to treat the documents we will add.
We use the FT.CREATE command, which has the syntax:
FT.CREATE <index_name> <field> [<score>|NUMERIC] …
Or in our example:
FT.CREATE products name 10.0 description 1.0 price NUMERIC
This means that name and description are treated as text fields with respective scores of 10 and 1, and that price is a numeric field used for filtering.
Now we can add new products to our index with the FT.ADD command:
FT.ADD <index_name> <doc_id> <score> FIELDS <field> <value> …
Adding a product:
FT.ADD products prod1 1.0 FIELDS
name “Acme 40-Inch 1080p LED TV”
description “Enjoy enhanced color and clarity with stunning Full HD 1080p”
price 277.99
The product is added immediately to the index and can now be found in future searches.
Now that we have added products to our index, searching is very simple:
FT.SEARCH products “full hd tv” LIMIT 0 10
Or with price filtering between $200 and $300:
FT.SEARCH products “full hd tv” FILTER price 200 300
The results are shown in the redis-cli as:
1) (integer) 1
2) “prod1”
3) 1) “name”
2) “Acme 40-Inch 1080p LED TV”
3) “description”
4) “Enjoy enhanced color and clarity with stunning Full HD 1080p at twice the resolution of standard HD TV”
5) “price”
6) “277.99”
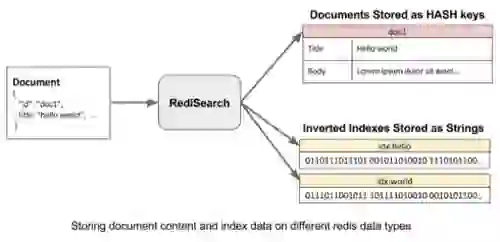
Our first design choice with RediSearch was to model Inverted Indexes using a custom data structure. This allows for more efficient encoding of the data, and possibly faster traversal and intersection of the index. We chose to simply use Redis string keys as binary encoded indexes, and read them directly from memory while searching, a technique that in the Modules API is called String DMA. We save document content, on the other hand, using plain old redis hash objects.
We save the Inverted Indexes in Redis using a technique that combines Delta Encoding and Varint Encoding to encode entries – minimizing space used for indexes, while keeping decompression and traversal efficient.
Another important feature for RediSearch is its auto-complete, or suggest, commands. This allows you to create dictionaries of weighted terms, and then query them for completion suggestions to a given user prefix. For example, if a user starts to put the term “lcd tv” into a dictionary, sending the prefix “lc” will return the full term as a result.
RediSearch also allows for Fuzzy Suggestions, meaning you can get suggestions to prefixes even if the user makes a typo in their prefix. This is enabled using a Levenshtein Automaton, allowing efficient searching of the dictionary for all terms within a maximal Levenshtein Distance of a term or prefix.
Here’s an example of creating and searching an auto-complete dictionary in RediSearch:
127.0.0.1:6379> FT.SUGADD completer “foo” 1
(integer) 1 127.0.0.1:6379> FT.SUGADD completer “football” 5
(integer) 2 127.0.0.1:6379> FT.SUGADD completer “fawlty towers” 7
(integer) 3 127.0.0.1:6379> FT.SUGADD completer “foo bar” 2
(integer) 4 127.0.0.1:6379> FT.SUGADD completer “fortune 500” 1
(integer) 5
127.0.0.1:6379> FT.SUGGET completer foo
1) “football”
2) “foo”
3) “foo bar”
127.0.0.1:6379> FT.SUGGET completer foo FUZZY
1) “football”
2) “foo”
3) “foo bar”
4) “fortune 500”
127.0.0.1:6379> FT.SUGGET completer faulty FUZZY
1) “fawlty towers”
To assess the performance of RediSearch compared to other open source search engines, we created a set of benchmarks measuring latency and throughput – while indexing and querying the same set of data.
Here are some of the results, showing RediSearch outperforming other open source search engines by significant margins (of course, as always, benchmarks results should be taken with a grain of salt. See the linked whitepaper for more results and info on the benchmarks):
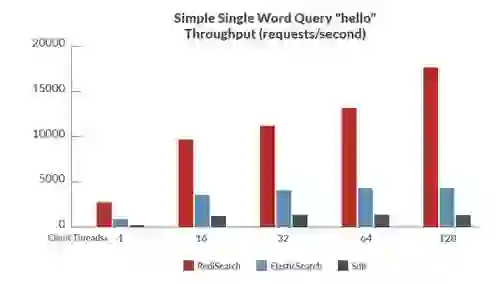
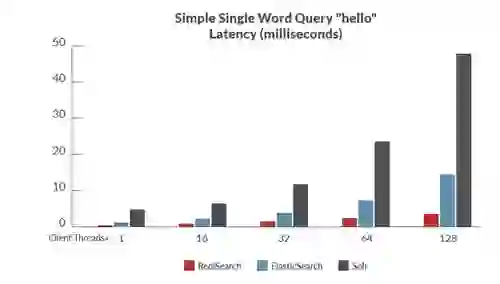
Benchmark 1: Easy single-word query – hello
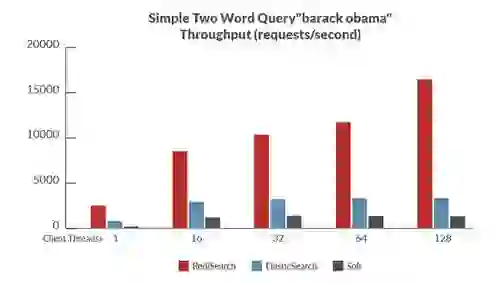
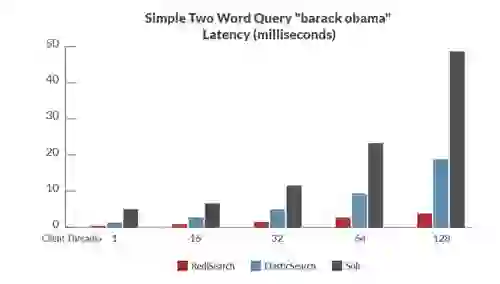
Benchmark 2: two word query – barack obama
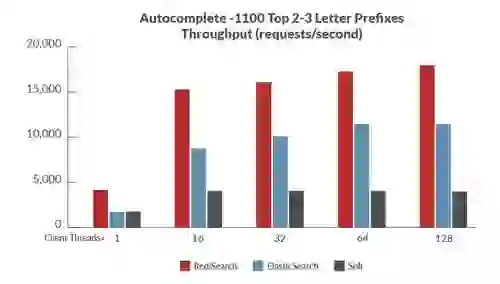
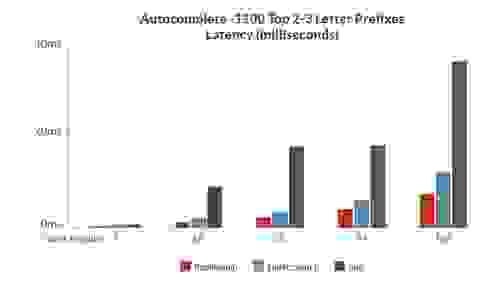
Benchmark 3: Autocomplete – 1100 top 2-3 letter prefixes in Wikipedia

